SQL Server backups on AWS EC2 using iSCSI shared storage
We recently had a customer contact us with an interesting use case – backing up Microsoft SQL Server to shared storage by using iSCSI. Most SoftNAS customers use NFS and CIFS in the cloud, and it has been less common to see iSCSI used on AWS EC2, so this caught my attention.
The Problem: SQL Server Backups in the cloud
The fundamental problem was backing up large SQL Server databases. SQL Server runs as a Windows service and cannot mount traditional Windows shares that require authentication within the domain. Other requirements included:
- – Completely deployed in cloud at AWS with SQL Server running on Amazon EC2
- – Silos of storage, hard drives per server (EBS mounted per individual instance)
- – Running into SQL Server database problems can necessitate backup recovery
- – EBS on SQL Server are striped for performance (RAID 0 x 12 drives)
- – Mounting of iSCSI from SQL Server to a shared storage server that would allow recovery later was desired
- – Provisioned IOPS with EBS optimization for high throughput
- – Full backups once per week
- – Incremental / differentials every 15 minutes
- – Windows file sharing – some services can’t write to CIFS share because it’s
- – Making backup and then copying over it (prior approach) – risks being down with no backup if failure occurs during backup
The Solution: SQL Server Backup storage in the cloud
The solution chosen was SoftNAS running on AWS. It supports iSCSI-mounted drives that look like a local disk to SQL Server, which can’t authenticate to a Windows share.
- – Using SoftNAS for backups of mission-critical SQL Server data
- – “What really caught my eye was iSCSI, eliminate network drive (looks like a local drive)”
- – “Was using EBS snapshots – lots of space, disorganized”
- – Using storage snapshots, which don’t take up additional space, and don’t overwrite prior versions
- – Deduplication and compression saves actual storage space
How to create the SQL Server Backup configuration
The following high-level steps can be used to create a SQL Server Backup server using SoftNAS:
1. Go to AWS Marketplace and launch a SoftNAS instance (a C3.Large instance should be sufficient to start)
2. Attach EBS volumes to the SoftNAS instance; e.g., attach 6 x 1 TB EBS volumes for around 5 TB usable space (or appropriate number of EBS volumes for your needs). If you need higher throughput, then configure the instance as an EBS optimized instance and enable EBS provisioned IOPS for higher throughput
3. In SoftNAS StorageCenter, partition the disk devices, then add them to create a Storage Pool using RAID 5 (RAIDZ1) for added data integrity. For higher write throughput, a RAID 10 configuration can be used instead.
4. In StorageCenter, choose Volumes and LUNs. Then Create Volume and assign the volume to the Storage Pool from step #3, and give it a volume name. Choose block device (LUN) as shown below:
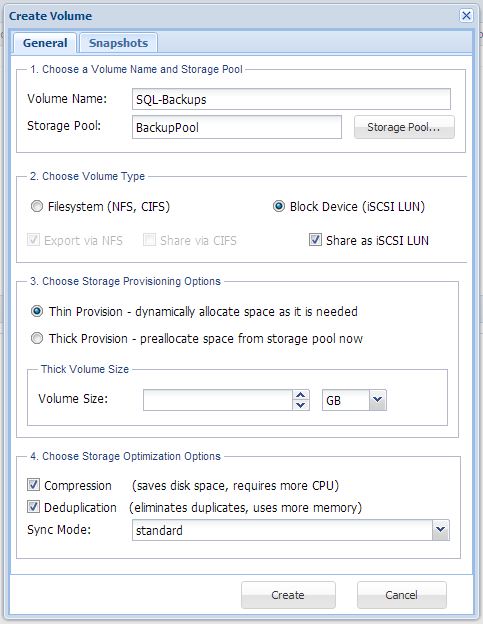
You can thin-provision the volume / LUN or choose a maximum size, which will preallocate the space from the storage pool and reserve that space for the LUN
When you press Create Volume, the LUN will be created, and it will be automatically assigned to the default iSCSI Targets (you can view in iSCSI Targets, where you can restrict access to the iSCSI Target by restricting access only the SQL Server or appropriate IP range)
5. On the Windows server that is running SQL Server, at the Start Menu (or in Control Panel) choose the iSCSI Initiator. Enter the private IP address of SoftNAS and choose “Quick Connect”. You should see the storage target appear in the list box. From here, you can Connect, Disconnect and view properties of the targets.
6. Using Server Manager, choose Storage > Disk Management. You will see a disk device that is unused. Use standard Windows disk drive device initialization and formatting (Initialize Disk, Create Disk, etc.) to create a Windows disk device using iSCSI, assigning it a drive letter.
At this point, you now have an iSCSI-mounted disk device on the SQL Server machine. The device appears like any other local disk drive to SQL Server, so there will be no authentication required by SQL Server when performing full or incremental backups.
7. Run a full backup of SQL Server on a weekly basis (for example), and schedule incremental backups every 15 minutes (or whatever best fits your needs). Also, ensure your transaction logs are saved, as needed.
Other factors you may want to consider:
- – Using compression and/or deduplication on the Volume / LUN settings to improve storage efficiency
- – Creating a custom snapshot schedule for the backup volume that better matches your backup recovery objectives
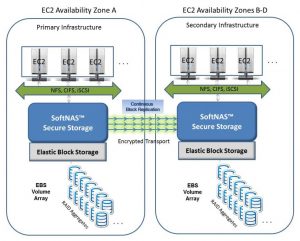
- – Using another SoftNAS instance in a different region (or availability zone) as an offsite DR backup
- – Use of S3 disk devices instead of EBS volumes, if less performance is required
The use of iSCSI in Windows to provide seamless access to shared storage provides a quick, efficient way to manage backups in the cloud for SQL Server and other databases. By combining iSCSI with NAS features like deduplication, compression and RAID, one can quickly create a cost-effective high-performance backup for SQL Server and SharePoint in the AWS cloud.
Many companies are moving SQL Server deployments to the cloud. If you are moving an app that is using SQL Server to the cloud, you will want to achieve the best performance possible, while keeping costs low. SoftNAS can be used in the cloud to optimize SQL performance and free up resources. By reducing resource load on the SQL Server businesses will benefit from lower SQL licensing costs, and reduce the cost associated with cloud storage.
Check Also:
Why SoftNAS Enterprise for Microsoft Azure?
Crank Up the Performance for Your Cloud Applications
Increase Reliability and Reduce Costs for Cloud Backups
Breaking the Million IOPS Barrier on AWS with NVMe for HPC