7 Cloud File Data Management Pitfalls and How to Avoid Them
7 Cloud File Data Management Pitfalls and How to Avoid Them
There are many compelling reasons to migrate applications and workloads to the cloud, from scalability and agility to easier maintenance. But anytime IT systems or applications go down it can prove incredibly costly to the business. Downtime costs between $100,000 to $450,000 per hour, depending upon the applications affected. And these costs do not account for the political costs or damage to a company’s brand and image with its customers and partners, especially if the outage becomes publicly visible and newsworthy.
Cloud File Data Management Pitfalls
“Through 2022, at least 95% of cloud security failures will be the customer’s fault,” says Jay Heiser, research vice president at Gartner. If you want to avoid being in that group, then you need to know the pitfalls to avoid. To that end here are seven traps that companies often fall into and what can be done to avoid them.
1. No data-protection strategy
It’s vital that your company data is safe at rest and in-transit. You need to be certain that it’s recoverable when (not if) the unexpected strikes. The cloud is no different than any other data center or IT infrastructure in that it’s built on hardware that will eventually fail. It’s managed by humans, who are prone to an occasional error, which is what typically has caused most major cloud outages over the past 5 years that I’ve seen on a large scale.
Consider the threats of data corruption, ransomware, accidental data deletion due to human error, or a buggy software update, coupled with unrecoverable failures in cloud infrastructure. If the worst should happen, you need a coherent, durable data protection strategy. Put it to the test to make sure it works.
Most native cloud file services provide limited data protection (other than replication) and no protection against corruption, deletion or ransomware. For example, if your data is stored in EFS on AWS® and files or a filesystem get deleted, corrupted or encrypted and ransomed, who are you going to call? How will you get your data back and business restored? If you call AWS Support, you may well get a nice apology, but you won’t get your data back. AWS and all the public cloud vendors provide excellent support, but they aren’t responsible for your data (you are).
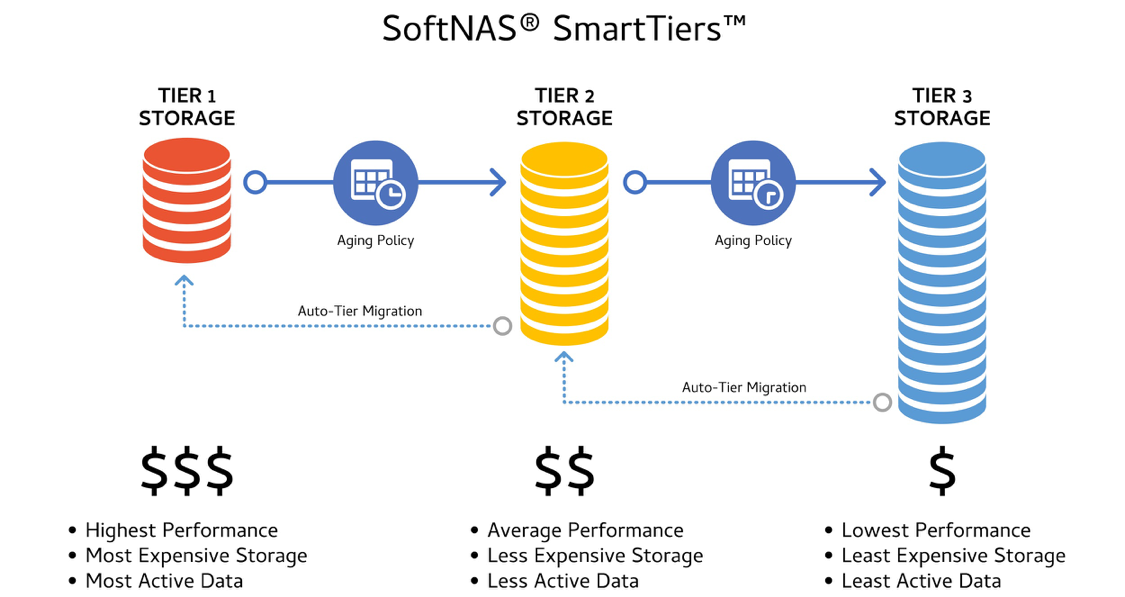
As shown below, a Cloud NAS with a copy-on-write (COW) filesystem, like ZFS, does not overwrite data. In this oversimplified example, we see data blocks A – D representing the current filesystem state. These data blocks are referenced via filesystem metadata that connects a file/directory to its underlying data blocks, as shown in a. As a second step, we see a Snapshot was taken, which is simply a copy of the pointers as shown in b. This is how “previous versions” work, like the ability on a Mac to use Time Machine to roll back and recover files or an entire system to an earlier point in time.
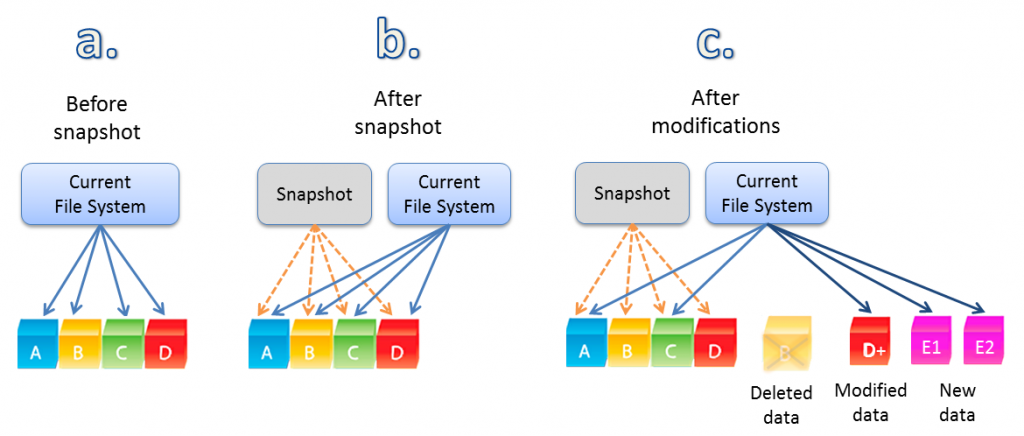
Anytime we modify the filesystem, instead of a read/modify/write of existing data blocks, we see new blocks are added in c. And we also see block D has been modified (copied, then modified and written), and the filesystem pointers now reference block D+, along with two new blocks E1 and E2. And block B has been “deleted” by removing its filesystem pointer from the current filesystem tip, yet the actual block B continues to exist unmodified as it’s referenced by the earlier Snapshot.
Copy on write filesystems use Snapshots to support rolling back in time to before a data loss event took place. In fact, the Snapshot itself can be copied and turned into what’s termed a “Writable Clone”, which is effectively a new branch of the filesystem as it existed at the time the Snapshot was taken. A clone contains a copy of all the data block pointers, not copies of the data blocks themselves.
Enterprise Cloud NAS products use COW filesystems and then automate management of scheduled snapshots, providing hourly, daily and weekly Snapshots. Each Snapshot provides a rapid means of recovery, without rolling a backup tape or other slow recovery method that can extend an outage by many hours or days, driving the downtime costs through the roof.
With COW, snapshots, and writable clones, it’s a matter of minutes to recover and get things back online, minimizing the outage impact and costs when it matters most. Use a COW filesystem that supports snapshots and previous versions. Before selecting a filesystem, make sure you understand what data protection features it provides. If your data and workload are business-critical, ensure the filesystem will protect you when the chips are down (you may not get a second chance if your data is lost and unrecoverable).
2. No data-security strategy
It’s common practice for the data in a cloud data center to be comingled and collocated on shared devices with countless other unknown entities. Cloud vendors may promise that your data is kept separately, but regulatory concerns demand that you make certain that nobody, including the cloud vendor, can access your precious business data.
Think about access that you control (e.g., Active Directory), because basic cloud file services often fail to provide the same user authentication or granular control as traditional IT systems. The Ponemon Institute puts the average global cost of a data breach at $3.92 million. You need a multi-layered data security and access control strategy to block unauthorized access and ensure your data is safely and securely stored in encrypted form wherever it may be.
Look for NFS and CIFS solutions that provide encryption for data both at rest and in flight, along with granular access control.
3. No rapid data-recovery strategy
With storage snapshots and previous versions managed by dedicated NAS appliance, rapid recovery from data corruption, deletion or other potentially catastrophic events is possible. This is a key reason that there are billions of dollars worth of NAS applications hosting on-premises data today.
But few cloud-native storage systems provide snapshotting or offer easy rollback to previous versions, leaving you reliant on current backups. And when you have many terabytes or more of filesystem data, restoring from a backup will take many hours to days. Obviously, restores from backups are not a rapid recovery strategy – it should be the path of last resort because it’s so slow and going to extend the outage by hours to days and the losses potentially into six-figures or more.
You need flexible, instant storage snapshots and writable clones that provide rapid recovery and rollback capabilities for business-critical data and applications. Below we see previous version snapshots represented as colored folders, along with auto pruning over time. With the push of a button, an admin can clone a snapshot instantly, creating a writable clone copy of the entire filesystem that shares all the same file data blocks using a new set of cloned pointers. Changes made to the cloned filesystem do not alter the original snapshot data blocks; instead, new data blocks are written via the COW filesystem semantics, as usual, keeping your data fully protected.
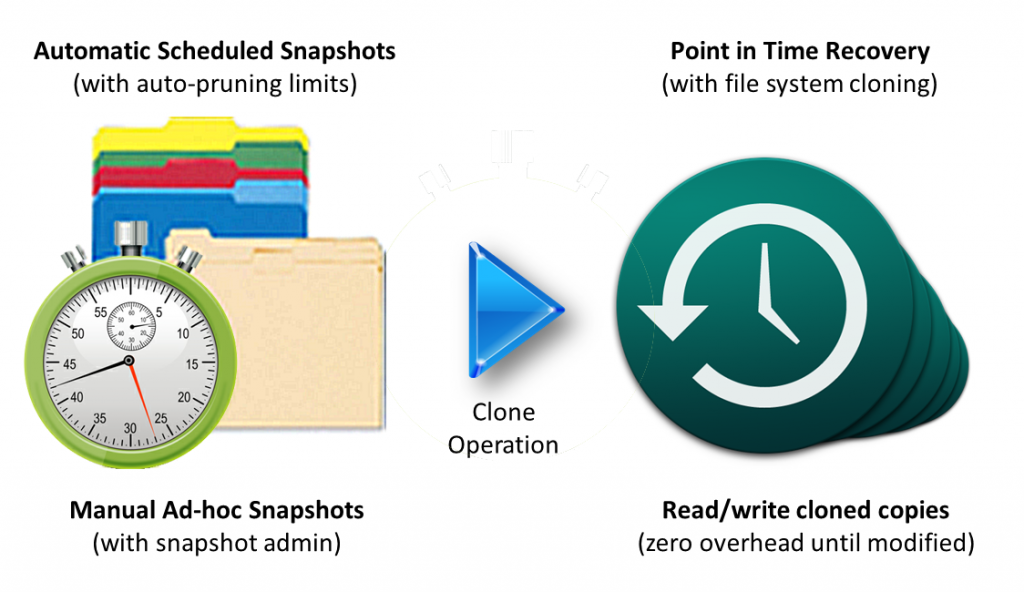
Ensure your data recovery strategy includes “instant snapshots” and “writable clones” using a COW filesystem. Note that what cloud vendors typically call snapshots are actually deep copies of disks, not consistent instant snapshots, so don’t be confused as they’re two totally different capabilities.
4. No data-performance strategy
Shared, multi-tenant infrastructure often leads to unpredictable performance. We hear the horror stories of unpredictable performance from customers all the time. Customers need “sustained performance” that can be counted on to meet SLAs.
Most cloud storage services lack the facilities to tune performance, other than adding more storage capacity, along with corresponding unnecessary costs. Too many simultaneous requests, network overloads, or equipment failures can lead to latency issues and sluggish performance in the shared filesystem services offered by the cloud vendors.
Look for a layer of performance control for your file data that enables all your applications and users to get the level of responsiveness that’s expected. You should also ensure that it can readily adapt as demand and budgets grow over time.
Cloud NAS filesystem products provide the flexibility to quickly adjust the right blend of (block) storage performance, memory for caching read-intensive workloads, and network speeds required to push the data at the optimal speed. There are several available “tuning knobs” to optimize the filesystem performance to best match your workload’s evolving needs, without overprovisioning storage capacity or costs.
Look for NFS and CIFS filesystems that offer the full spectrum of performance tuning options that keep you in control of your workload’s performance over time, without breaking the bank as your data storage capacity ramps and accelerates.
5. No data-availability strategy
Hardware fails, people commit errors, and occasional outages are an unfortunate fact of life. It’s best to plan for the worst, create replicas of your most important data and establish a means to quickly switch over whenever sporadic failure comes calling.
Look for a cloud or storage vendor willing to provide an SLA guarantee that matches your business needs and supports the SLA you provide to your customers. Where necessary create a failsafe option, with a secondary storage replica to ensure your applications do not experience any outage and instead a rapid HA failover occurs instead of an outage.
In the cloud, you can get 5-9’s high availability from solutions that replicate your data across two availability zones; i.e., 5 minutes or less of unplanned downtime per year. Ask your filesystem vendor to provide a copy of their SLA and uptime guarantee to ensure it’s aligned with the SLAs your business team requires to meet its own SLA obligations.
6. No multi-cloud interoperability strategy
As many as 90% of organizations will adopt a hybrid infrastructure by 2020, according to Gartner analysts. There are plenty of positive driving forces as companies look to optimize efficiency and control costs, but you must properly assess your options and the impact on your business. Consider the ease with which you can switch vendors in the future and any code that may have to be rewritten. Cloud platforms entangle you with proprietary APIs and services, but you need to keep your data and applications multi-cloud capable to stay agile and preserve choice.
You may be delighted with your cloud platform vendor today and have no expectations of making a change, but it’s just a matter of time until something happens that causes you to need a multi-cloud capability. For example, your company acquires or merges with another business that brings a different cloud vendor to the table and you’re faced with the need to either integrate or interoperate. Be prepared as most businesses will end up in a multi-cloud mode of operation.
7. No disaster-recovery strategy
A simple mistake where a developer accidentally pushes a code drop into a public repository and forgets to remove the company’s cloud access keys from the code could be enough to compromise your data and business. It definitely happens. Sometimes the hackers who gain access are benign, other times they are destructive and delete things. In the worst case, everything in your account could be affected.
Maybe your provider will someday be hacked and lose your data and backups. You are responsible and will be held accountable, even though the cause is external. Are you prepared? How will you respond to such an unexpected DR event?
It’s critically important to keep redundant, offsite copies of everything required to fully restart your IT infrastructure in the event of a disaster or full-on hacker attack break-in.
The temptation to cut corners and keep costs down with data management is understandable, but it is dangerous, short-term thinking that could end up costing you a great deal more in the long run. Take the time to craft the right DR and backup strategy and put those processes in place, test them periodically to ensure they’re working, and you can mitigate these risks.
For example, should your cloud root account somehow get compromised, is there a fail-safe copy of your data and cloud configuration stored in a second, independent cloud (or at least a different cloud account) you can fall back on? DR is like an insurance policy – you only get it to protect against the unthinkable, which nobody expects will happen to them… until it does. Determine the right level of DR preparedness and make those investments. DR costs should not be huge in the cloud since most everything (except the data) is on-demand.
Conclusions
We have seen how putting the right data management plans in place ahead of an outage will make the difference between a small blip on the IT and business radars vs. a potentially lengthy outage that costs hundreds of thousands to millions of dollars – and more when we consider the intangible losses and career impacts that can arise. Most businesses that have operated their own data centers know these things, but are these same measures being implemented in the cloud?
The cloud offers us many shortcuts to quickly get operational. After all, the cloud platform vendors want your workloads running and billing hours on their cloud as soon as possible. Unfortunately, choosing naively upfront may get your workloads migrated faster and up and running on schedule, but in the long run, cost you and your company dearly.
Use the above cloud file data management strategies to avoid the 7 most common pitfalls. Learn more about how SoftNAS Cloud NAS helps you address all 7 of these data management areas.