by Buurst Staff | AWS, Microsoft Azure
SoftNAS began its life in the cloud and rapidly rose to become the #1 best-selling NAS in the AWS cloud in 2014, a leadership position we have maintained and continue to build upon today. We and our customers have been operating cloud native since 2013, when we originally launched on AWS. Over that time, we have helped thousands of customers move everything from mission-critical applications to entire data centers of applications and infrastructure into the cloud. In 2015, we expanded support to Microsoft Azure, which has become a tremendous area of growth for our business.
By working closely with so many customers with greatly varying environments over the years, we’ve learned a lot as an organization – about the challenges customers face in the cloud – and getting to the cloud in the first place with big loads of data in the hundreds of terabytes to petabyte scale.
Aside from security, the biggest challenge area tends to be the network – the Internet. Hybrid cloud uses a mixture of on-premises and public cloud services with data transfers and messaging orchestration between them, so it all relies on the networks. Cloud migrations must often navigate various corporate networks and the WAN, in addition to the Internet.
The Internet is the data transmission system for the cloud, like power lines distribute power throughout the electrical grid. While the Internet has certainly improved over the years, it’s still the wild west of networking.
The network is the Achilles heel of the cloud.
Developers tend to assume that components of an application are operating in close proximity of one another; i.e., a few milliseconds away across reliable networks, and if there’s an issue, TCP/IP will handle retries and recover from any errors. That’s the context many applications get developed in, so it’s little surprise that the network becomes such a sore spot.
In reality, production cloud applications must hold up to higher, more stringent standards of security and performance than when everything ran wholly contained within our own data centers over leased lines with conditioning and predictable performance. And the business still expects SLA’s to be met.
Hybrid clouds increasingly make use of site-to-site VPN’s and/or encrypted SSL tunnels through which web services integrate third party and SaaS sites and interoperate with cloud platform services. Public cloud provider networks tend to be very high quality between their data center regions, particularly when communications remain on the same continent and within the same provider. For those needing low-latency tunnels, AWS DirectConnect and Azure ExpressRoute can provide additional conditioning for a modest fee, if they’re available where you need them.
But what about the corporate WAN, which are often overloaded and plagued by latency and congestion? What about all those remote offices, branch offices, global manufacturing facilities and other remote stations that aren’t operating on pristine networks and remain unreachable by cost-effective network conditioning options?
Latency, congestion and packet loss are the usual culprits
It’s easy to overlook the fact that hybrid cloud applications, bulk data transfers and data integrations take place globally. And globally it’s common to see latencies in the many hundreds of milliseconds, with packet loss in the several percent range or higher.
In the US, we take our excellent networks for granted. The rest of the world’s networks aren’t always up to par with what we have grown accustomed to in pure cloud use cases, especially where many remote facilities are located. It’s common to see latency in the 200 to 300 milliseconds range when communicating globally. When dealing with satellite, wireless or radio communications, latency and packet loss is even greater.
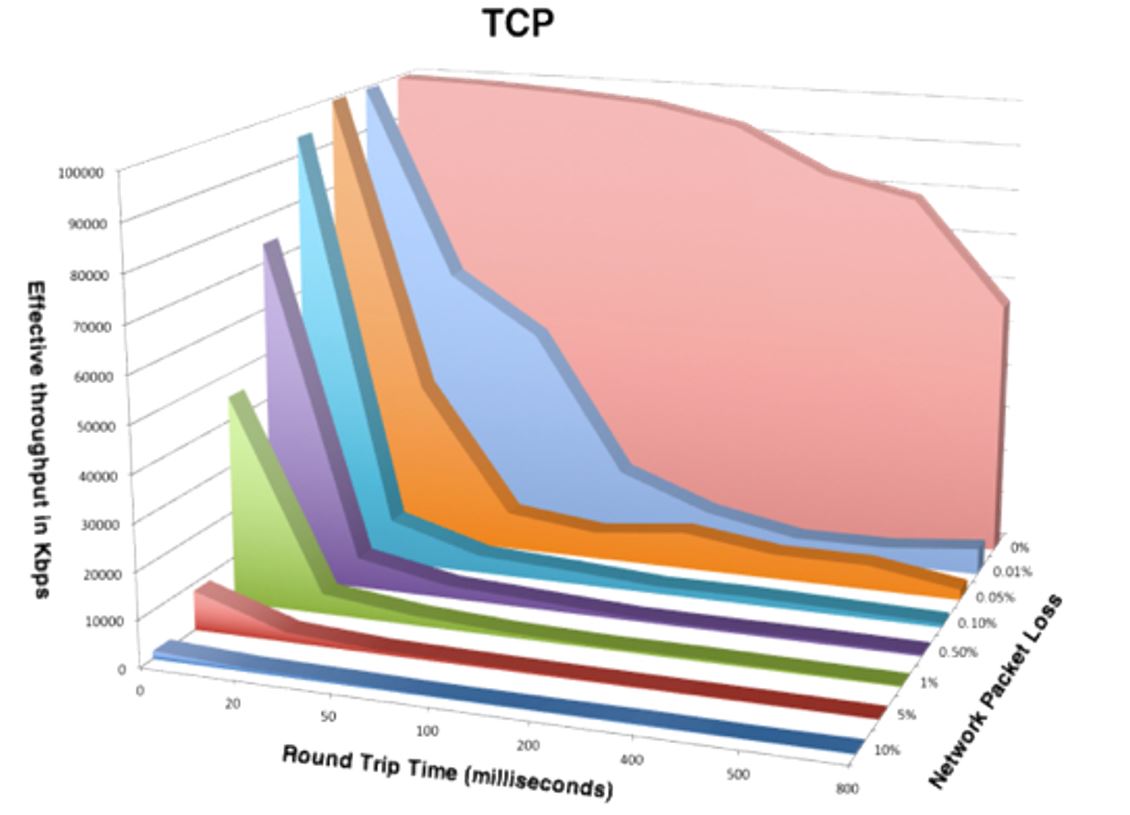
Unfortunately, the lingua franca of the Internet is TCP over IP; that is, TCP/IP. Here’s a chart that shows what happens to TCP/IP in the face of latency and packet loss resulting from common congestion.

The X axis represents round trip latency in milliseconds, with the Y axis showing effective throughput in Kbps up to 1 Gbps, along with network packet loss in percent along the right side. It’s easy to see how rapidly TCP throughput degrades when facing more than 40 to 60 milliseconds of latency with even a tiny bit of packet loss. And if packet loss is more than a few tenths of a percent, forget about using TCP/IP at all for any significant data transfers – it becomes virtually unusable.
Congestion and packet loss are the real killer for TCP-based communications. And since TCP/IP is used for most everything today, it can affect most modern network services and hybrid cloud operation.
This is because the TCP windowing algorithm was designed to prioritize reliable delivery over throughput and performance. Here’s how it works. Each time there’s a lost packet, TCP cuts its “window” buffer size in half, reducing the number of packets being sent and slowing the throughput rate. When operating over less than pristine global networks, sporadic packet loss is very common. It’s problematic when one must transfer large amounts of data to and from the cloud. TCP/IP’s susceptibility to latency and congestion render it unusable. This well-known problem has been addressed on some networks by deploying specialized “WAN Optimizer” appliances, so this isn’t a new problem – it’s one IT managers and architects are all too familiar with and have been combating for many years.
Latency and packet loss turn data transfers from hours into days, and days into weeks and months
So even though we may have paid for a 1 Gbps network pipe, latency and congestion conspire with TCP/IP to limit actual throughput to a fraction of what it would be otherwise; e.g., just a few hundred kilobits per second. When you are moving gigabytes to terabytes of data to and from the cloud or between remote locations or over the hybrid cloud, what should take minutes takes hours, and days turn into weeks or months.
We regularly see these issues with customers who are migrating large amounts of data from their on-premises datacenters over the WAN and Internet into the public cloud. A 50TB migration project that should take a few weeks turns into 6 to 8 months, dragging out migration projects, causing elongated content freezes and sending manpower and cost overruns through the roof vs. what was originally planned and budgeted.
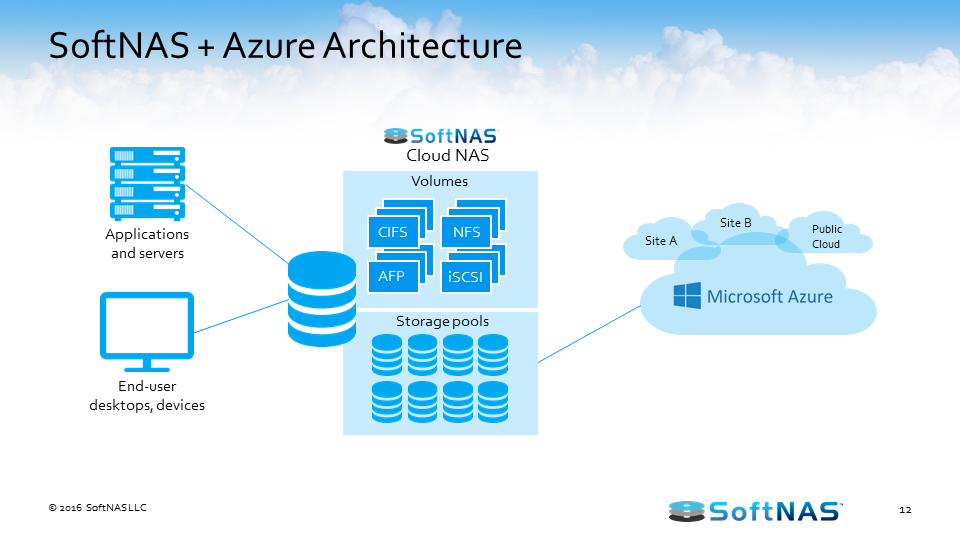
As we continued to repeatedly wait for customer data to arrive in the public cloud to complete cloud migration projects involving SoftNAS Cloud NAS, we realized this problem was acute and needed to be addressed. We had many customers approach us and ask us if we had thought about helping in this area – as far back as 2014. Several even suggested we have a look at IBM Aspera, which they said was a great solution.
In late 2014, we kicked off what turned into a several year R&D project to address this problem area. Our original attempts were to use machine learning to automatically adapt and adjust dynamically to latency and congestion conditions. That approach failed to yield the kind of results we wanted.
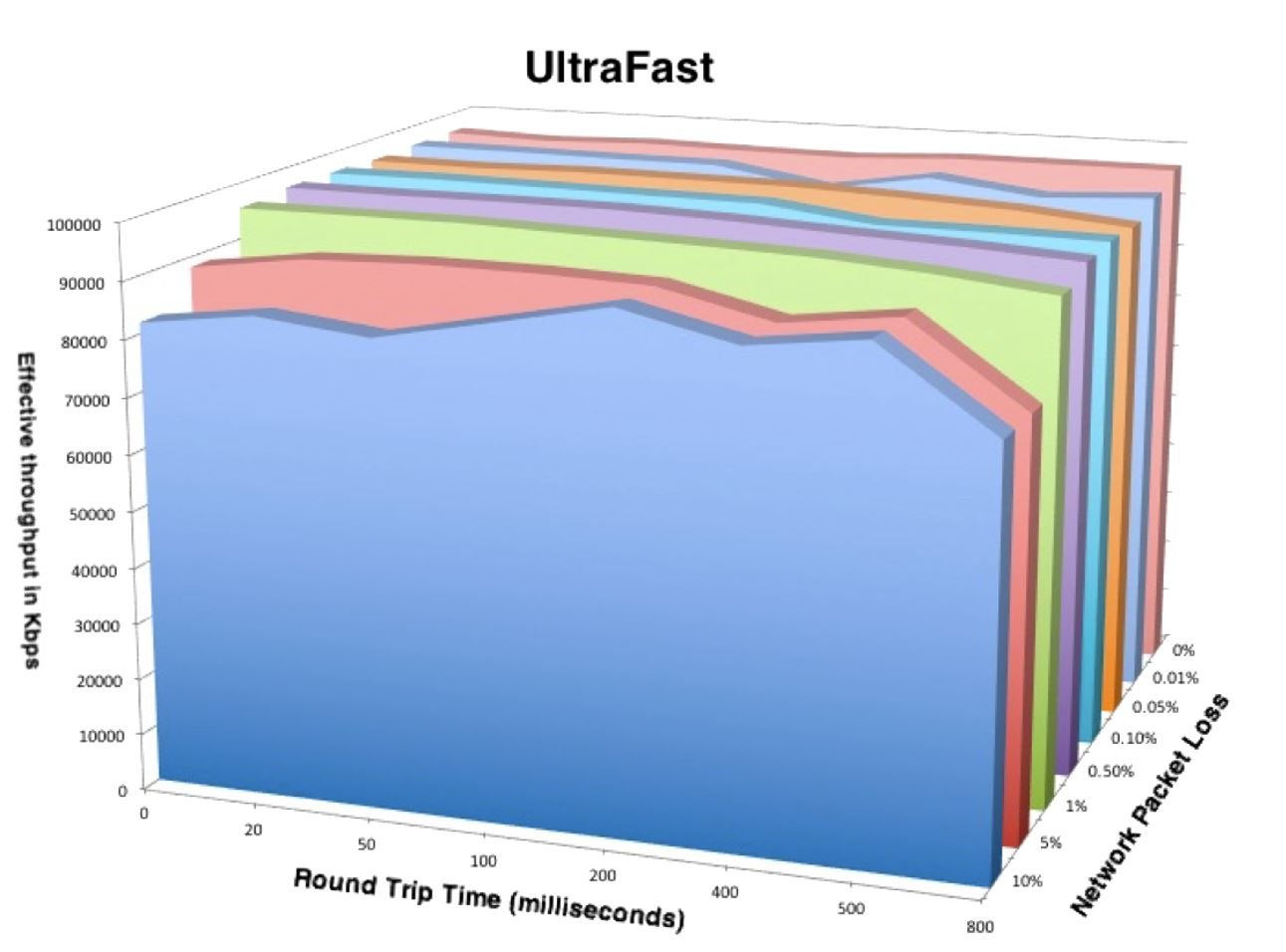
Eventually, we ended up inventing a completely new network congestion algorithm (that’s now Ultra pending patent) to break through and achieve the kind of results we see below.
We call this technology “UltraFast™.”

As can be easily seen here, UltraFast overcomes both latency and packet loss to achieve 90% or higher throughput, even when facing up to 800 milliseconds and several percent packet loss. Even when packet loss is in the 5% to 10% range, UltraFast continues to get the data through these dirty network conditions.
I’ll save the details of how UltraFast does this for another blog post, but suffice it to say here that it uses a “congestion discriminator” that provides the optimization guidance. The congestion discriminator determines the ideal maximum rate to send packets without causing congestion and packet loss. And since TCP/IP constantly re-routes packets globally, the algorithm quickly adapts and optimizes for whatever path(s) the data ends up taking over IP networks end-to-end.
What UltraFast means for cloud migrations
We combine UltraFast technology with what we call “Lift and Shift” data replication and orchestration. This combo makes migration of business applications and data into the public cloud from anywhere in the world a faster, easier operation. The user simply answers some questions about the data migration project by filling in some wizard forms, then the Lift and Shift system handles the entire migration, including acceleration using UltraFast. This makes moving terabytes of data globally a simple job any IT or DevOps person can do.
Additionally, we designed Lift and Shift for “live migration”, so once it replicates a full backup copy of the data from on-premise into the cloud, it then refreshes that data so the copy in the cloud remains synchronized with the live production data still running on-premise. And if there’s a network burp along the way, everything automatically resumes from where it left off, so the replication job doesn’t have to start over each time there’s a network issue of some kind.
Lift and Shift and UltraFast take a lot of the pain and waiting out of cloud migrations and global data movement. It took us several years to perfect it, but now it’s finally here.
What UltraFast means for global data movement and hybrid cloud
UltraFast can be combined with FlexFiles™, our flexible file replication capabilities, to move bulk data around to and from anywhere globally. Transfers can be point-to-point, one to many (1-M) and/or many to one (M-1). There is no limitation on the topologies that can be configured and deployed.
Finally, UltraFast can be used with Apache NiFi, so that any kind of data can be transferred and integrated anywhere in the world, over any kind of network conditions.
SUMMARY
The network is the Achilles heel of the cloud. Internet and WAN latency, congestion and packet loss prevent hybrid cloud performance, timely and cost-effective cloud migrations and slow global data integration and bulk data transfers.
SoftNAS’ new UltraFast technology, combined with Lift and Shift migration and Apache NiFi data integration and data flow management capabilities yield a flexible, powerful set of tools for solving what have historically been expensive and difficult problems with an purely software solution that runs everywhere; i.e., on VMware or VMware-compatible hypervisors and in the AWS and Azure clouds. This powerful combination puts IT in the driver’s seat and in control of its data, overcoming the cloud’s Achilles heel.
NEXT STEPS
Visit Buurst, Inc to learn more about how SoftNAS is used by thousands of organizations around the world to protect their business data in the cloud, achieve a 100% up-time SLA for business-critical applications and move applications, data and workloads into the cloud with confidence. Register here to learn more and for early access to UltraFast, Lift and Shift, FlexFiles and NiFi technologies.
ABOUT THE AUTHOR
Rick Braddy is an innovator, leader and visionary with more than 30 years of technology experience and a proven track record of taking on business and technology challenges and making high-stakes decisions. Rick is a serial entrepreneur and former Chief Technology Officer of the CITRIX Systems XenApp and XenDesktop group and former Group Architect with BMC Software. During his 6 years with CITRIX, Rick led the product management, architecture, business and technology strategy teams that helped the company grow from a $425 million, single-product company into a leading, diversified global enterprise software company with more than $1 billion in annual revenues. Rick is also a United States Air Force veteran, with military experience in top-secret cryptographic voice and data systems at NORAD / Cheyenne Mountain Complex. Rick is responsible for SoftNAS business and technology strategy, marketing and R&D.

by Buurst Staff | AWS, Microsoft Azure
The IT Archaeological Dig of Technology and the Cloud
I must admit something right up front here – I love technology! I’m a techno-geek on most every level, in addition to having done a lot of other stuff in my career and personally with technology. Most people don’t know, but I recently got my ham radio license again after being inactive for 45 years… but that’s another story. One of my latest radio projects I’ve been working on after hours for almost a year involves what is essentially an IoT device for ham radio antennas.
I find technology relaxing and satisfying, especially electronics, where I can get away from the stresses of business and such and just focus on getting that next surface mount component properly soldered. Given my busy schedule, I make slow but unrelenting progress on these types of background projects, but it beats wasting away in front of the TV. In fact, I should probably order one of these hats from propellerhats.com and wear it proudly.

As a bit of background on this blog post, when I was CTO at CITRIX Systems, I used the term “archaeological dig of technology” to describe the many layers of technology deposits that I saw our customers had deployed and that we continue to see companies dealing with today. The term caught on internally and even our then CEO, Mark Templeton, picked up on and it and used it from time to time, so the term stuck and resonated with other technologists over the years. Mark and I had a friendly competition going to see who could come up with the coolest tech. Mark usually won, being the real chief propeller head. We had a lot of fun winning and growing CITRIX together in those days…
So, what do I mean by the Archaeological Dig of Technology aka “The Dig”? I would describe it as the sum total of technologies that have been deposited within an enterprise over time.
The Dig is the result of buying and deploying packaged applications, in-house applications, external service integration, mergers and acquisitions and other forms of incrementalism adding technology acquisition and automation to our businesses over time. It’s surprising how much technology accumulates with time.
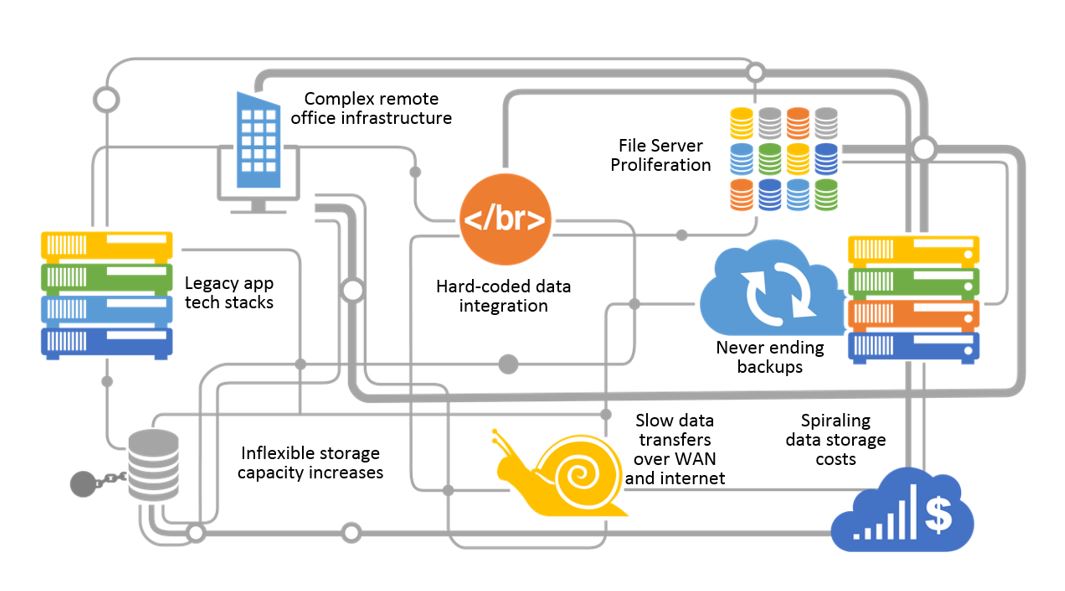
The following diagram attempts to depict a typical dig one might find at companies today. It’s by no means complete, but merely attempts to illustrate some of the components and complexities involved. For most, this is probably an oversimplified perspective highlighting the types of technologies and related issues that have accrued.

What we see above is a complex set of application stacks running across virtual machines, physical servers, and data stored across various proprietary vendor storage gear. There’s numerous hard-coded data integration paths across applications, technology stacks and SaaS providers, tentacles to and from remote offices, branch offices and offshore manufacturing facilities spread around globally. The challenge with global data and the cloud is the latency and congestion that limits us over the WAN and Internet.
File servers have proliferated around the world into most every nook and cranny they could fit. And now there’s so much data piling up to be protected that for many large enterprises, weekly full backups have turned into monthly backups and the wall of data keeps getting higher. Customers tell us that they see the day coming when even monthly full backups won’t be feasible. The costs continue to mount and there’s no end in sight for most growing companies today.
For large enterprises, the term “dig” doesn’t adequately describe the full breadth and depth of the technological sediment involved, which is truly expansive. For these companies, there are numerous Digs, spread across many data centers, subsidiaries and physical locations – and clouds.
For small to medium size companies, it’s amazing how many types of technologies we have deployed and integrated together to run our businesses. While much less complex than The Digs of larger enterprises, relative to our size our digs are often just as challenging with our limited resources, and are often outsourced to someone else to deal with.
If we think about the bottommost layer of The Dig as the earliest forms of technology we acquired, for many that is still the mainframe. It’s amazing how many companies still rely on mainframe technology for much of their most critical transaction processing infrastructure. This brings with it various middleware that links mainframe beast computing with everything else.
Unlike minicomputers, which went the way of the dinosaur quickly, client-server and PC era technologies followed and stuck, comprising a large portion of most enterprises’ digs today. Citrix helped hundreds of thousands to organize and centralize most of the client-server layer, so it’s now contained in the data centers and continuing to serve the business well today.
Web technology layers came next and became a prevalent layer that remains centralized for all users, ranging from B2C, B2B and B2E via SaaS layers that sit outside our data centers in someone else’s digs.
Then we realized we have too many servers and they’re not all busy doing work, yet they take up space and cost money to maintain and power up 24 x 7. Enter the virtualization and server consolidation era, and the next major new layer reorganized The Dig into a more manageable set of chunks affectionately known as Virtual Machines. VM’s made life sweet, because we can now see most of The Dig on one console and manage it by pushing a few buttons. This is very cool! VMware ushered in this era and owns most of this layer today.
Of course, Apple, Google and others ushered in the mobile computing era, another prevalent and recent layer that’s rapidly evolving and bringing richness to our world. To make things easier and more convenient, Wi-Fi and 3G then 4G and next 5G wireless networks came to the rescue to tie it all together for us and make our tech world available 24 x 7 everywhere we go.
IoT is now on the horizon and promises to open amazing new frontiers by melding our physical world increasingly with the virtual one we work and live in. We have the Big Data and data warehouses and analytics systems to try and make sense of everything, as the number of layers and complexity of The Dig becomes overwhelming as it accelerates in size, data growth and the intensity of complexity stresses our abilities to understand, manage and keep it all secure. Speaking of security, there’s entire other layers which are there solely so The Dig doesn’t get infiltrated and pilfered endlessly.
Unfortunately for many, as we have seen all too often in recent news, for some The Dig has been penetrated by hackers, exposing some of our most precious personal information to the bad guys. As if that’s not disturbing enough, we find out that encryption, that layer which insulates us from the bad guys in cyberspace, is compromised at the edge with our Wi-Fi devices!
So, what’s the next layer? Obviously, the clouds, machine learning and someday real Artificial Intelligence. And we already hear the pundits telling us that AI will change everything! Of course, it will. Maybe it will figure out how to reorganize The Dig for us, too!
Underneath these big animal picture layers, we have the actual underlying technologies. Now I’m not going to attempt to provide a complete taxonomy or list here, but it’s the entire gamut of devices and appliances deployed today, including mainframes, middleware, client-server, virtual servers, cloud servers, Citrix servers, provisioning and deployment tools, systems management, e-commerce systems, networking, firewalls, plus programming tools and stacks (.NET, JAVA, MFC, C++, PHP, Python, …) and traditional operating systems like Linux, Windows, Mac OS X, iOS, Android, … and the list just keeps going (way too long to list here).
What I find most amusing is how the vendor marketing hype cycle invariably tries to convince us that this latest technology wave will be the “be all, end all” that will take over and replace everything! Nope – not even close. It’s just the next layer of The Dig being promoted for immediate adoption and installment. It will either replace an earlier layer or (more likely) add a new layer atop the existing Dig and bring with it new tentacles of integration and complexities of its own.
Perhaps an obvious question to ask is “how could this happen?” or “what can be done to keep The Dig from spiraling out of control?” or “who’s responsible for this and making sure it doesn’t happen?”
My guess is we may not like the answers to those kinds of questions. It happens because companies need to compete, adapt and move quickly to grow. Each technology acquisition decision is usually treated as a discrete event that addresses a current set of priorities and issues evaluated in isolation, but nobody is truly responsible for or capable of managing The Dig strategy overall. I mean, who has the title “The Dig Director” or “The Chief Dig Officer”?
Ultimately, IT is typically held responsible for keeping The Dig running, updated, patched, secured, performing well, available and operational to meet the business’ needs. IT is sometimes, but certainly not always, consulted about the next set of layers that are about to be deposited. But increasingly, IT inherits the latest layers and admits them into The Dig and becomes the custodian who’s responsible for running and maintaining it all (with something like 2% to 3% annual budget increase).
So where does “the cloud” fit into this picture? Good question. I suspect if you ask some, they will tell you “finally, the cloud is the one that will replace them all!” Right. Of course, it will. I mean, we’ve been waiting for a long time, surely this must be it! The Dig will be completely “digitally transformed”, replacing all that those other messy, pesky layers that we no longer want or respect like we once did.
Others will probably say the cloud is just one of many IT strategies we have, which is probably closer to reality for most companies, at least over the short haul.
I wish it were really that simple. In reality, “the cloud” isn’t a single thing. There’s public clouds, private clouds, hybrid clouds and SaaS clouds – and each one is yet another layer coming to pile onto The Dig and create a new set of interesting technologies for us moving forward. Most companies can only muster enough budget and resource to rewrite a few apps per year to “digitally transform” pieces of The Dig into the new world order we seek. Alas, rewriting all the apps to Java didn’t work out in the end, so can we really digitally transform everything before the next big thing appears to disrupt our progress?
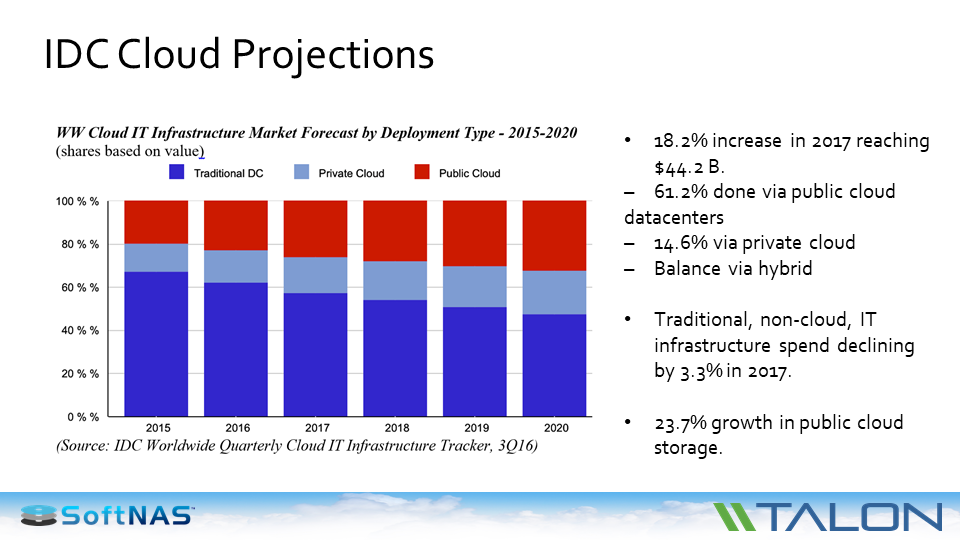
Multi-cloud is the next reality coming to The Dig near you. The facts are that most companies expect to deploy across many different clouds (up to 10 or more!) and link everything together via various “hybrid cloud” layers… just a friendly heads up – it’s coming soon to The Dig near you. As shown below, industry analysts tell us that 80% of the decision-makers are already committed to adding hybrid clouds and 60% expect to operate multi-cloud environments in 2018.

This means we know what’s coming next to The Dig near us – more layers.
So, what can be done about The Dig we have today, and the new layers being regularly deposited? For most companies, little to nothing. Each layer serves a purpose, adding value to our businesses. Mergers and acquisitions aren’t going to stop. Business units will continue to hire DevOps and Shadow IT to quickly develop new applications, integrate business processes with new cloud services with multiple vendors and then add it to the corporate technology collective.
For smaller to medium size corporations, there’s hope in that much of their technologies can be migrated to one or more public cloud and SaaS platforms. For others, it’s incrementalism-as-usual – do what we must today, it’ll be someone else’s problem to deal with in the future – there’s no strategy other than survive to live another day.
When we step back and consider what seems like a chaotic process full of uncontrolled variables and incremental decisions, I believe there’s hope to eventually unwind from the hairball architectures and reorganize our respective technology digs to make them more manageable.
One of the keys is “virtualization”. The cloud is really a combination of virtual computing and platform services that’s both backward compatible and forward leaning; meaning, we can migrate our existing VM workloads into the cloud and run them, while we lean forward and create new services and applications by tapping into cloud platform services. But is that the be all, end all that’s needed? Probably not.
We need a “data strategy”. I believe there is an elemental piece that’s been missing – the Data Virtualization layer, a data access and control layer that makes business data more portable across storage systems, clouds, SaaS clouds, databases, IoT devices and the many other data islands we have today and will add to The Dig over time.
To achieve the multi-cloud and hybrid cloud diversity and integration that many believe come next, without creating more brittle hairball architectures, there must be a recognition that “data is the foundation” that everything rests upon.
If data remains corralled up and tied down to discrete, platform-specific “storage” devices, applications will never be truly freed up to become portable, multi-cloud or hybrid-cloud. Even clever innovations like modular micro-services and reusable containers will continue to be platform constrained until the data layer is virtualized and made flexible enough to quickly and easily adapt with the evolution to the multi-cloud.
In future posts, I will share details around the SoftNAS “cloud fabric” vision and what we now call the “Cloud Data Platform”, a data control layer that enables rapid construction of hybrid clouds, IoT integration and interconnecting the existing layers of The Dig across multiple clouds.
The Dig will continue to be with us, supporting our businesses as we grow and evolve with technology. It’s clear at this point that the next set of layers will be cloud-based. We will need to integrate the many existing layers globally with the cloud, while we incrementally evolve and settle into our new digs in the cloud era.
NEXT STEPS
Visit Buurst to learn more about how SoftNAS is used by thousands of organizations around the world to protect their business data in the cloud, achieve a 100% up-time SLA for business-critical applications and move applications, data and workloads into the cloud with confidence. Register here to learn more and for early access to the Cloud Data Platform, the new data access and control plane from SoftNAS.
ABOUT THE AUTHOR
Rick Braddy is an innovator, leader and visionary with more than 30 years of technology experience and a proven track record of taking on business and technology challenges and making high-stakes decisions. Rick is a serial entrepreneur and former Chief Technology Officer of the CITRIX Systems XenApp and XenDesktop group and former Group Architect with BMC Software. During his 6 years with CITRIX, Rick led the product management, architecture, business and technology strategy teams that helped the company grow from a $425 million, single-product company into a leading, diversified global enterprise software company with more than $1 billion in annual revenues. Rick is also a United States Air Force veteran, with military experience in top-secret cryptographic voice and data systems at NORAD / Cheyenne Mountain Complex. Rick is responsible for SoftNAS business and technology strategy, marketing and R&D.